I’m not sure how many of you have used the MERGE statement, it comes from SQL:2003 standard but for SQL Server it was first released with version 2008, so it’s been around for a while now.
This guy right here is very useful when you need to either insert new rows, update, ALL. IN. ONE, that’s why it’s also called UPSERT in other DBMS. The difference with all other engines, is that Microsoft included one proprietary extension of the clause called WHEN NOT MATCHED BY SOURCE.
HOW IT WORKS?
The MERGE statement uses a “source” table which is the one we’re going to get the data from; and a “target” table, where we’re going to insert or update the data.
Let’s see an example.
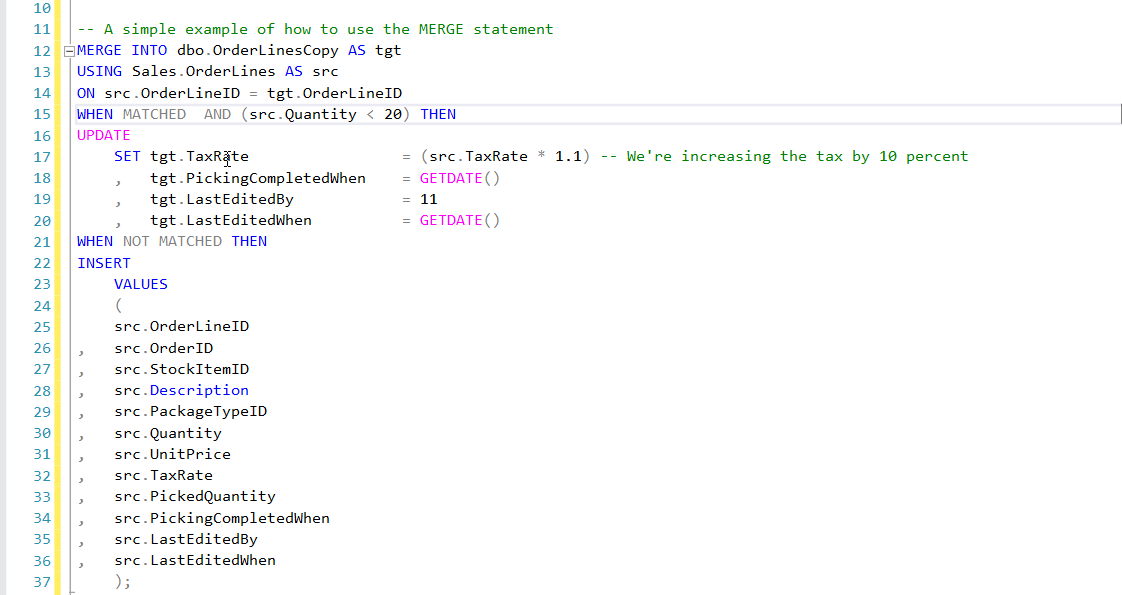
In this example we can see the syntax and structure of a very simple use of the MERGE statement. I previously created an empty copy of the Sales.OrderLines table from WideWorldImporters database, and this copy is the what I’m using as a target table.
After executing the statement, the resulting rows must be the same since our OrderLinesCopy table was empty. If we run a COUNT on both tables we can see they have the same number of rows.
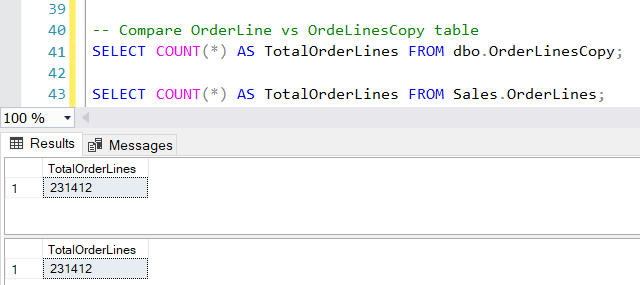
I’m going to execute the statement again and see what happens. Note that in the statement, I’m only looking for existing rows that have less than 20 items in the order, this will update the TaxRate by 10% and the user, the picking date and the last edit date. Let’s see how that works out.

The query returned 133,747 rows, which is the number of order lines that have less than 20 items. So, it worked!
BUT, WHAT IF…?
We’ve already saw the structure and how the MERGE statement works when you need to INSERT or UPDATE records from your source to the target table. But, what happens when for some reason, we need to compare every one of the columns from the source and target in order to update the row? Like this:

I’ve seen cases where all the columns need to be compared in order to update the row like that. In this example I only added very few columns, but what if we are doing this in the fact table of a Data Warehouse and we have more than 100 columns there? That doesn’t seem like very efficient, and I don’t think the developer would like to do that. Until now…
THE TRICK
There are several operators that we just forget about. One of them uses a distinctness in the comparison, which will be very useful then dealing with NULLS, because a NULL is distinct from a non-NULL value, but is not distinct from another NULL.
I’m talking about the EXCEPT operator, and the way it works is that when there is a difference between the source and the target, the operator will return a row. We’re going to be using the EXCEPT operator together with the EXISTS predicate in order to do this trick.
See where i’m going? If the EXCEPT return a row, then the EXISTS will return true, assuming there is something different, hence, applying the update.
To understand better what’s going on, let’s see an example.

In the example above, I’ve already applied the EXISTS predicate and the EXCEPT operator. See that I also included the OUTPUT clause in order to know what was going on with my data. After executing the statement again, this is the result.

133,747 rows were updated, and in the picture we can see what was updated which is basically the PickingCompletedWhen and the LastEditedWhen columns.
Note that I’m still using very few columns, but in case you need to compare all the columns from your tables, you can do this.

That’s all for today’s post. I really hope that you guys have learned something useful to make your jobs easier and more enjoyable. There are still more to talk about the MERGE statement, but I’ll leave that for another day.
You can find the code for this and previous posts in the link below:
https://github.com/learningsql/sql-code
Also, if you don’t have the WorldWideImporters database, you can get it here:
https://github.com/microsoft/sql-server-samples/tree/master/samples/databases/wide-world-importers
Don’t forget to like and share. See you soon.
Discover more from Ben Rodríguez
Subscribe to get the latest posts sent to your email.